


Like all websites, GOV.UK sometimes experiences technical difficulties. These can be caused by bugs in code, unexpected inputs, heavy system load, or any combination of the above. Issues like these are inevitable. What we can control is how we spot and resolve them quickly.
In recent months, we’ve reduced our error count by over 90%. This has already enabled us to discover new issues which were previously lost in the noise. We’ve also improved the developer experience by integrating error reporting with Slack and improving our documentation. We’ve engaged with other teams to encourage a targeted approach to Slack alerts, to keep our overall error count low.
How we track errors
At GOV.UK, we track errors using an external service called Sentry. This is a monitoring platform that logs unexpected things occurring on GOV.UK. It gives us detailed information for each event, and this lets GOV.UK developers work out what the issue is and how to resolve it. Other monitoring tools are available; for an explanation of why we chose Sentry, see this discussion on GitHub.
We found that we were getting an extremely high number of errors each week, making it hard to navigate Sentry. The high number of errors also meant that Sentry was not storing all of the errors we were sending, as there is a cap on the number of events Sentry will allow per hour. Events over the threshold get discarded (‘rate-limited’), giving developers no information to go on, and in the worst case scenario, no indication that there is an issue at all.
We needed to reduce our error count on Sentry to bring us under the rate limit, and to make sure we could spot and deal with new issues as quickly as possible. This blog post explains the 3 steps we took to do this and how we reduced our error count by over 90%.
What we wanted to improve
While GOV.UK looks like a single website, it is actually formed of over 50 frontend and backend applications which are hosted and maintained independently. For much of 2020, we were regularly logging 100,000 to 200,000 weekly errors across these applications. This sounds extremely high but many of these could be attributed to a handful of distinct ‘issues’. Sentry groups events into issues, making it easy to quantify how often the problem occurs. It is also possible to write comments on issues, and assign issues to developers.
The high number of issues made Sentry noisy. This wasn’t helped by the fact that a lot of the issues seemed to be duplicated, with issues with the same title appearing multiple times in the list. We wanted to investigate how Sentry groups its issues to see whether we could configure it to do a better job.
The high number of issues was exacerbated by having one shared GOV.UK Sentry account for all of our environments. An issue on a test environment could bring us over the rate limit and therefore hamper logging on production. It was critical that we reduce the number of events we send to remain below the threshold, so that issues wouldn’t get lost in the system.
Finally, we needed a preventative strategy to stop the number of events from creeping up again.
Investigating Sentry grouping
By default, Sentry groups issues by stack trace, and if no stack trace is available, it will also look at the exception type/message. However, Sentry also allows you to customise how you group issues, by specifying your own fingerprinting algorithm, or changing the setting in the user interface.
We investigated whether custom grouping would be beneficial, by auditing all unresolved issues and considering which ones should be grouped. Our audit showed many of the issues that looked like duplicates actually referred to different controllers and templates, so were in fact separate issues, even if they looked similar.
The audit did highlight one problem: some duplicate issues resulted from harmless dependency upgrades, because the file structure of the dependency would change slightly, changing the stack trace (which Sentry uses to group issues). Really, these ‘framework traces’ aren’t very helpful for issue grouping; what we care about is the ‘application trace’.
It is possible to ‘clean up’ the stack trace prior to sending it to Sentry, but doing so would cause the original stack trace to never get logged, losing valuable diagnostic information. We’ve raised a feature request with Sentry to use only the application trace for issue grouping, whilst still logging the full stack trace.
We concluded that, on balance, Sentry’s default grouping algorithm works quite well for us.
Reducing the events sent to Sentry
To recap, we were logging too many errors, which meant that we had no visibility of errors that occurred over the rate-limit.
We created a Grafana dashboard to monitor our errors in Sentry over time, so we could measure how well we were tackling the problem. We also created a separate dashboard for errors in what was our most error-producing application.
This application was consistently logging almost 15,000 errors to Sentry every day. Though high in volume, most of the errors were attributed to a single issue, which only appeared to be happening during the nightly data sync.
Every night, all content on GOV.UK gets copied to our staging and integration environments. This is achieved by dropping and re-creating databases, meaning that some services on these environments can be temporarily unavailable, and any attempt to make a call to them results in an error. These particular errors are harmless, expected and unactionable, so we wanted to stop them from being logged to Sentry.
We decided to implement a new configuration option: a list of exception types that should be ignored if they occurred during the data sync. This was added into our GovukError module, which our applications use to interface with Sentry. The effect was immediate: errors in the most error-producing application dropped by 98%.
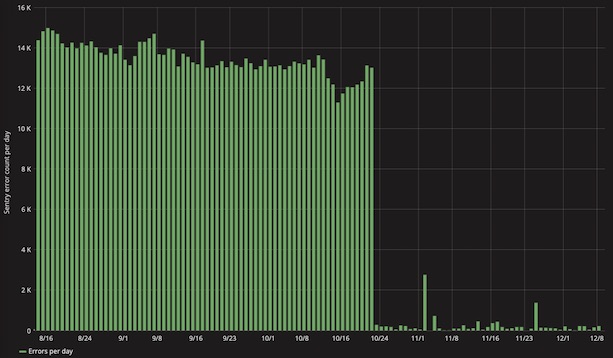
One application consistently logged almost 15,000 errors per day until we applied a fix that almost eliminated them overnight.
We continued to audit Sentry, writing up the most prolific issues for developers in the Platform Health team to work on, then ‘ignoring’ the issue in the Sentry user interface. This meant the errors were still being logged but were no longer as visible, which helped reduce the noise and enabled us to spot new issues as they arose. We’d ‘resolve’ the issue once we’d fixed the problem: this is a useful mechanism as Sentry emails the resolver of the issue if the problem comes back.
Over time, we resolved the highest volume issues and made other improvements to our default configuration, such as only allowing errors from particular environments. We also became more particular about what should get logged in Sentry, only allowing actionable system errors, and not, for example, errors caused by the user.
We succeeded in bringing our overall error count far below the rate limiting threshold. Our best week was in March 2021, where we logged just 5,500 errors; a significant reduction on the more than 100,000 errors we were regularly seeing beforehand.
We now needed to start thinking about a preventative strategy, to avoid error counts from climbing again.
Preventative strategy
Whilst all of our developers have Sentry access, they typically only log into Sentry during an incident, or to keep an eye on the health of an application when deploying. This makes it easy for new issues to creep in unnoticed.
Sentry has a Slack integration which sends notifications when events occur, according to configured alert rules. We created an alert to notify us when an issue occurs more than 100 times in the space of 60 minutes. We’ve found that this strikes the right balance, as it prioritises our worst errors whilst avoiding spamming the channel. We hope to gradually lower this threshold so that we can work through the ‘long tail’ of issues.
One problem with these notifications is that they aren’t targeted: they rely on someone monitoring the channel and taking ownership of the issue. Many issues arise as a result of code changes made outside of our team, and it would be far more efficient to directly notify the team or developer responsible for the change. We’re therefore encouraging other teams on GOV.UK to set up their own Slack alerts for the applications that they regularly work on, which we hope will prevent the introduction of most new errors.
Next steps
In the short term, we next hope to improve the production alerts that page our second line and on-call developers when something on GOV.UK needs an urgent response. Beyond this, we’re thinking about how we might introduce more observability to GOV.UK: we’ve recently introduced Real User Monitoring, and are considering options such as Application Performance Management. Our ongoing replatforming project presents an exciting opportunity to design these processes from the ground up.
Interested in the work here? We’re hiring developers at GOV.UK - come join us! Go to the GDS Careers page for more information.

There are countless Easter eggs hidden throughout Google products, whether they’re online or in various apps. Recently, a new one was discovered within the Google app on iOS that lets you play a pinball/brick breaker game.
The post Google app for iOS hides a fun pinball game Easter egg; here’s how to access it appeared first on 9to5Mac.
Sure, it is kind of funny to see KFC get in an argument with Wendy's on Twitter, but what's really going on here? Is this even good marketing? As brands like this try to get personal with customers and each other, what kind of post-ironic soap opera is this? This is weird right? Like, it's kind of funny but this is mostly weird?
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
Submitted by:




, dark mode (disables screen), screaming mode (self-explanatory), and coherent ultracapacitor-pumped emission (please let us know what this setting does; we've been afraid to try it).")

1 public comment

New phone OS features: Infinite customization (home screen icons no longer snap to grid), dark mode (disables screen), screaming mode (self-explanatory), and coherent ultracapacitor-pumped emission (please let us know what this setting does; we've been afraid to try it).

At GDS, we’ve always promoted the benefits of working in multidisciplinary teams, being co-located as much as possible. Bringing together specialists to work on problems in the same building has clear benefits: interaction is easier, scrum boards and roadmaps are more visible and make coordination more fluid, and collaboration can be kicked off quickly.
But we’re keen on the benefits of remote working too. Teams can choose to work from home, flexibly, as needed, and everyone is given the tools to do so. It means they can get their head down and focus, or do the washing up at lunchtime in between meetings. People can find a balance between work and life that works for them.
All that changed in late March when everyone shifted to working from home by default. We wanted to take advantage of the change to try new working practices in GOV.UK Pay, inspired by a blog post about how they communicate asynchronously at Automattic.
So we tried to have a week where there was nothing that demanded that people be in a certain place at a certain time and making sure our messages were clear and comprehensible, giving people time to think and respond, and having more agency over how they spent their time.
Getting rid of meetings
The biggest change was to get rid of work meetings. Meetings force people to do a specific thing at a specific time, potentially disrupting their flow. We wanted to see what happened when there were no meetings in the calendar.
For our trial, there were some exceptions:
- meetings with people outside Pay, which might have been unavoidable
- community and line management meetings, which aren’t relevant to a team trial
- meetings for pair programming or collaborative work, to do something together rather than to decide something
Several team ceremonies we would have usually held in a meeting, such as retrospectives (retros) or sprint planning, were substituted by colleagues providing their own updates on collaborative tools, such as team Slack channels, Google Docs or Trello boards. Tasks were assigned in similar ways.
There wasn’t a team show-and-tell scheduled for the asynchronous week, but we could have explored sharing pre-recorded segments and discussing them on Slack.
Getting rid of emails
Email is a form of asynchronous communication, but has a few characteristics that would make the trial harder:
- it’s “push” communication, so the recipient can’t opt in and out
- it’s closed, so only the recipients can see the information and the sender needs to pre-empt everyone who might need it
- it’s basic, so things like version control and comment threads get complex fast
Instead, people sent messages on a team Slack channel, or created proposals in Google Docs and shared that.
Keeping things ticking over
One benefit of removing meetings is that we no longer had a reason to say people had to work specific hours. We asked everyone to work the same number of hours that they usually do, but asked them to do them at any time and in any length of blocks that they like. The exception to this was people working on Support, who had to work the times set out in our support agreement with our users.
We scheduled 2 optional social meetings a day to stay connected as a team, with a strict no-work-talk rule (so we didn’t compromise the experiment).
How it went
We ran a retro to reflect on the week, voting on various things, as well as gathering comments. Not everyone voted on everything, so the numbers are inconsistent.
On balance, more people found this way of working to be as good as or better than normal. 8 people had mostly positive feelings about working in this way. 6 were neutral or conflicted, and 2 had mostly negative feelings.
On the whole, we managed to follow the rules: 17 of 18 people broke the rules once or twice at most.
The biggest benefit for most people was having bigger blocks of free time, which allowed them to focus on a piece of work without interruption. Almost everyone found that managing their own concentration levels was easier.
The clunkiest bit of the week was planning. Each team usually spends time on working out what to do next every week, and some teams do so daily.
Most of this could have happened in Slack, but without scheduled meetings, some of it didn’t. Each team did put together a sprint backlog, but it was generally less well thought out than usual. However, 11 of 12 people thought this clunkiness was probably lack of practice, rather than a fundamental trait of asynchronous planning.
One team usually pairs all day. They struggled with the absence of a stand-up to coordinate the pairing in the morning, and to connect with the wider direction of their work.
What we learned
The trial highlighted some things that otherwise weren’t obvious.
We noticed a few instances where a process was usually collectively owned, but without a meeting to force people to engage with it, it didn’t get done. In those instances, a named person or role responsible for the process would have helped. We’ll explore whether we’d work better with a defined owner or rota for those processes, even when working synchronously.
At one point, an urgent piece of work arrived and we tried to adapt asynchronous processes to deal with it, but quickly abandoned that. When the cycle time for sensing a problem and providing a response is short, direct communication and collaboration makes it quicker to deliver solutions.
Some felt less engaged with their team, which is something we’d need to solve if we were to switch to this pattern in the long term.
The benefits people experienced tended to be related to their role. For example, product managers, delivery managers and designers generally have competing priorities for how to spend their time. An absence of meetings empowered them to prioritise freely, rather than having to spend time on whatever felt important when meetings were scheduled. Developers tend to work more directly from a backlog, so felt this benefit less.
Next steps
The way that remote working has blended people’s experience of work and home together is challenging.
Some find it helpful to emulate the experience of going to an office as closely as possible. That might be by doing things like only working during normal working hours, and going for a walk before and after work to replace the wind-down effect of a commute.
However, not everyone works at their best in this way all the time. Some find it easier to work in several smaller chunks through the day and evening, or get up late and sleep late, or take a 3-hour lunch break and extend the day. We want to be as flexible as possible, and reducing the number of meetings in the calendar helps to do that.
A popular idea in the retro was to have dedicated days each week when meetings were banned, and after a follow-up survey, we now have no team meetings on Tuesdays or Fridays. We’ll review this regularly to see if we’d like more or fewer days in the future.
We’ll keep reevaluating our ways of working. Whenever the option of working in the same space is available again, we’ll jointly decide what we want that to look like and how we can accommodate every individual’s needs. Though we’d love to be near each other again, we’ll probably never go back to working exactly how we used to.
Next Page of Stories